




 AI编辑工作室
完整覆盖出版编印全流程
AI编辑工作室
完整覆盖出版编印全流程
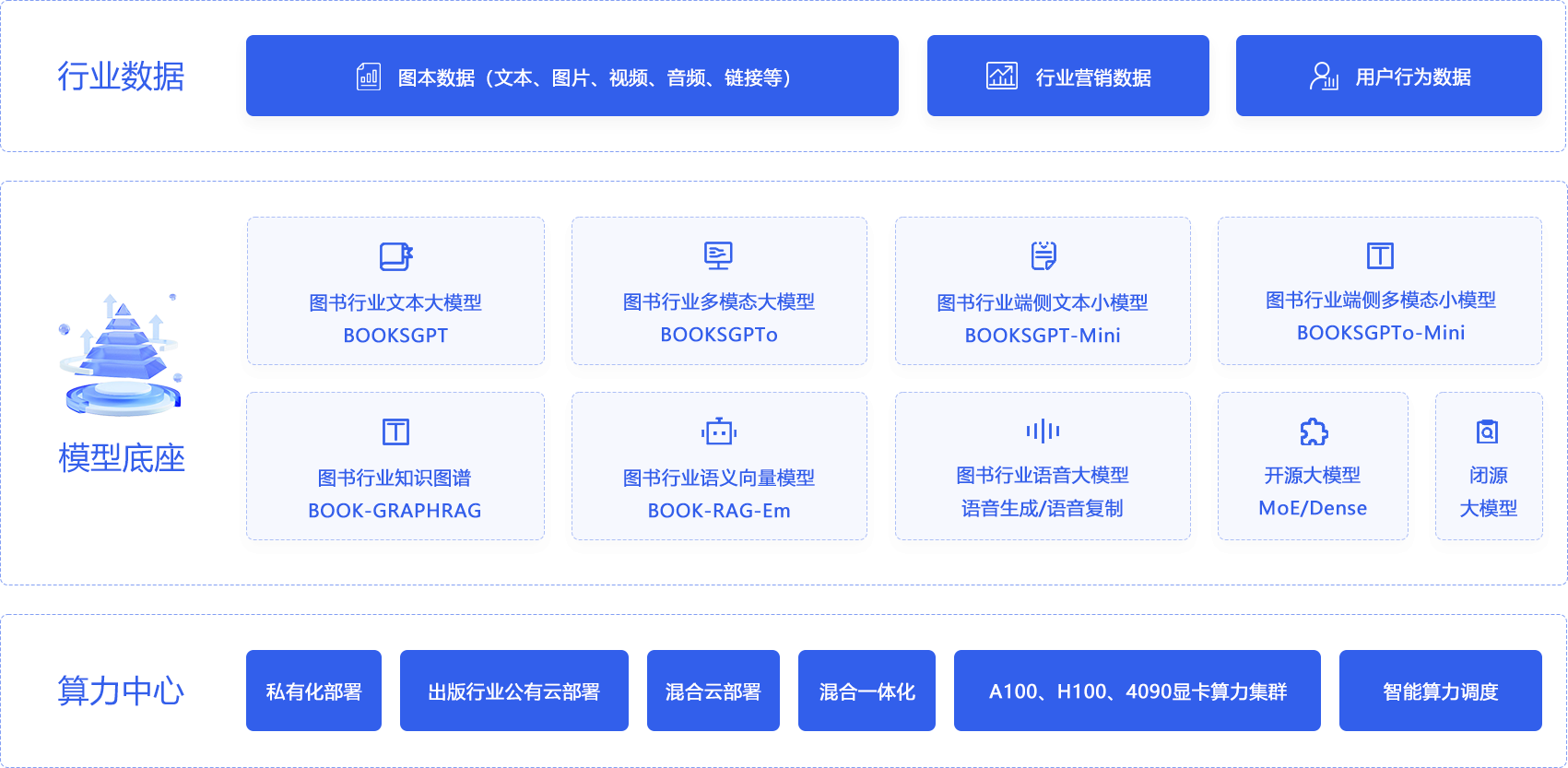
 AI RAYS
全国首个图书AI数智化平台
AI RAYS
全国首个图书AI数智化平台
 “书小二” AI裂变套件
基于图书潜在读者的AI裂变套件
“书小二” AI裂变套件
基于图书潜在读者的AI裂变套件
 “书船” 新媒体图书营销
“书船” 新媒体图书营销